eBPF(Extended Berkeley Packet Filter)란?
eBPF를 설명하기 전에 BPF(Berkeley Packet Filter)는 네트워크 트래픽을 분석해야 하는 프로그램을 위해 특정 OS에서 사용되는 기술입니다. 이름 그대로 패킷을 걸러내는 필터입니다.
BPF의 핵심은 프로그램을 작성해서 아래 그림과 같이 커널 내 몆몆 지점에서 돌릴 수 있다는 것입니다. (그래서 구글 프로젝트 제로의 Spectre 설명에도 (e)BPF가 등장합니다.) 유연성과 편의성 간 타협이라는 측면에서 커널 프로그래밍과 커널 이용 사이의 영역을 채워 줍니다. 꽤 편하면서도 유연한 메커니즘이 있는데 사람들이 가만 놔뒀을 리 없겠죠. 패킷 대신 다른 선형 데이터를 프로그램 입력으로 주고 반환 값 해석 방식을 나름대로 정하면 다른 모듈에서도 BPF를 사용할 수 있습니다.
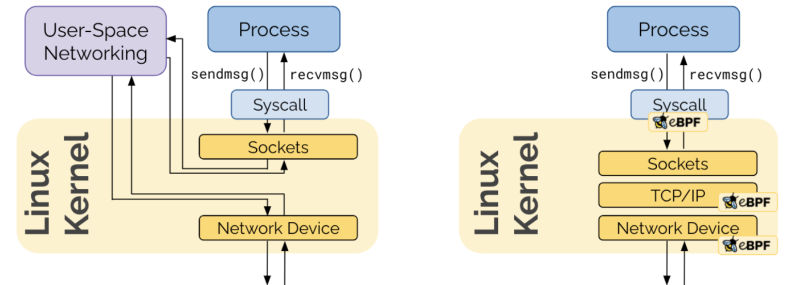
eBPF(Extended Berkeley Packet Filter)는 BPF의 확장된 기술로 커널 소스 코드를 바꾸거나 추가 모듈을 추가할 필요 없이 프로그램을 OS 커널 공간에서 실행하는 기술입니다. 현재, 관찰가능성(observability)은 주로 수동으로 실행합니다. 텔레메트리 데이터를 생성하려면 적정 지점에 코드를 추가해야 하므로 심각한 장벽이 되는 경우가 많고, 어떤 기업은 아예 시도조차 할 수 없다. 자동 에이전트가 존재하기는 하지만 특정 프로그래밍 언어와 프레임워크에 맞춰지는 경향이 있습니다.
반면, eBPF를 활용하면 바로 OS 커널 수준부터 전체 소프트웨어 스택에 걸쳐 노코드 관찰가능성을 구현할 수 있습니다. 쿠버네티스(Kubernetes) 환경 내에 관찰가능성이 수월해지고 네트워킹 및 보안 부분에도 장점이 생기게 됩니다.
eBPF는 다양한 종류의 트래픽에 걸쳐 작동하므로 통합 관찰가능성이라는 기업의 목표를 달성하는 데 큰 도움이 됩니다. 예를 들어, 데브옵스 엔지니어는 전체 트레이스 요청, 데이터베이스 질의, HTTP 요청, gRPC 스트림 수집은 물론 CPU 사용량이나 전송 바이트 수와 같은 자원 활용 지표(메트릭스) 수집에도 eBPF를 활용할 수 있습니. 따라서 해당 기업은 관련 통계를 산출하고 데이터의 개요를 파악해 다양한 기능의 자원 소모 현황을 이해할 수 있게 됩니다. 또한, eBPF는 암호화된 트래픽을 처리할 수 있습니다.
넷플릭스에서 최근 게시한 블로그를 보면, eBPF를 활용해 네트워크 인사이트를 얻는 방식을 알 수 있습니다. 넷플릭스에 따르면 eBPF는 어느 인스턴스에서든 CPU와 메모리 소비가 1퍼센트 미만일 정도로 사용 효율성이 매우 높습니다.
eBPF동작 방식
BPF는 Kernel에 Sandbox 형태로 설치되어 Packet을 필터링, 즉 Packet에 대한 제어를 할 수 있습니다.
BPF는 Packet Filtering하고 분석하는데 주로 사용되며 BPF가 사용되는 대표적인 예는 tcpdump에서 사용하는 필터링으로 볼 수 있습니다.
이러한 BPF를 확장한 eBPF(extended BPF)가 나왔으며 eBPF는 Linux Kernel에 내장되어 시스템의 변경 없이 단순히 시스템 호출을 통해 요청을 처리 합니다.
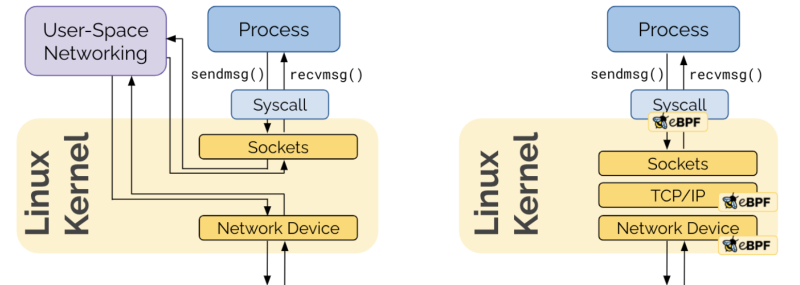
기존의 Packet 처리는 좌측의 그림처럼 Kernel과 Userspace의 iptables를 거치게 되는 불필요한 오버헤드가 발생하지만 eBPF는 Kernel에 내장되어 있어 Kernel-level에서 Packet에 대한 Filtering 등을 처리 할 수 있습니다.
따라서, 앞에서 언급한 iptables의 의존도를 낮출(또는 iptables 없이)뿐만 아니라 Kubernetes에서 eBPF를 사용하는 이유는 다양하지만 주 된 이유는 다음과 같습니다.
Performance
기존의 iptables 규칙은 Service와 Pod가 증가하는 만큼 규칙의 수는 기하 급수적으로 증가하기 때문에 규칙에 일치할 때 까지 모든 규칙을 다 검사해야하는데 많은 시간이 소요 되는 만큼 지연이 발생합니다. 또한, iptables의 규칙 업데이트가 발생하면 전체 iptables의 규칙을 교체하는데 많은 시간이 소요됩니다.
반면에 eBPF는 iptables를 사용하지 않고 eBPF를 통해 Packet을 처리하여 앞에서 언급한 문제점을 제거할 수 있습니다.
Tracing
BPF를 사용하면 Pod와 Container-level 의 Packet 추적과 네트워크 통계가 가능합니다.
Host의 Kernel에 구성되는 eBPF가 Container-level에서 Packet 처리를 하는 부분에 대해 많은 의문이 생길 수 있습니다. Pod에는 eBPF가 설치되지 않기 때문이죠.
이러한 부분이 가능한 이유는 다음과 같습니다.
Host(Node)에 구성되는 eBPF가 Pod 또는 Container 수준의 Tracing이 가능한 이유는 Host와 Pod가 같은 cgroup Namespace를 사용하며 해당 Namespace에 'cgroup-bpf' 프로그램을 사용하기 때문입니다.
즉, cgroup의 Process에서 들어오고 나가는 모든 Packet에 대해 BPF를 실행 할 수 있습니다.
'IT > Linux OS' 카테고리의 다른 글
| [Linux] ssh에 config를 설정하여 쉽게 서버 접근하기 (0) | 2024.01.02 |
|---|---|
| [Linux] iptables 동작 방식 (0) | 2022.08.24 |
| [Linux] yum repository 설정하기 (0) | 2022.02.28 |
| [리눅스] date 명령어 사용하기 (format 활용법 yyyy-mm-dd) (0) | 2022.02.16 |
| [리눅스] 다중명령어 (더블엔퍼센트&&, 더블버티컬바||) (0) | 2022.02.16 |
