iptables 동작 방식
Kubernetes Cluster에서 Routing을 이해하기 위해서는 iptables의 동작을 이해하는 것이 매우 중요 합니다. iptables를 통해 Packet이 처리 되는 과정에 대해서 이해하고 eBPF에 대해서 확인하도록 하겠습니다.
iptables(Userpspace)은 Netfilter(Kernel)과 함께 동작합니다. Packet을 처리하는 과정에서 Netfilter Hook이 트리거 되어 관련된 iptables의 Chain의 규칙을 평가 합니다.
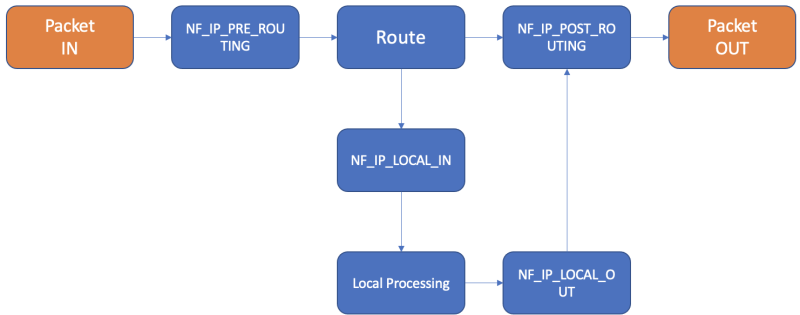
위의 그림에서 Packet이 Node로 들어오면서 해당 Packet이 처리 되는 과정에서 Netfilter Hook을 트리거 하게 되고 해당 Hook과 연결 된 iptables Chain이 실행이 됩니다.
Packet이 처음 Node의 Kernel에 도착하게 되면 가장 먼저 NF_IP_PRE_ROUTING hook이 트리거가 되면서 iptables의 PREROUTING Chain이 실행 됩니다.

iptables PREROUTING Chain (위 그림의 다른 Subchain은 Calico와 DOCKER가 만든것이기 때문에 신경쓰지 않으셔도 됩니다.)
해당 iptables Chain으로 이동하면 kube-proxy가 생성한 "KUBE-SERVICES" subchain으로 다시 이동합니다.
"KUBE-SERVICES" Chain에는 아래와 같이 NordPort Service와 관련 된 규칙이 존재 합니다. (이러한 규칙들은 앞서 언급한 것처럼 모든 Node에 동일하게 설정)

위의 KUBE-SERVICES Chain의 규칙 중에서 요청 Pakcet의 Destination IP(ClusterIP)와 Port가 일치하는 경우, 해당 Packet은 해당 Destination IP(ClusterIP)와 관련 된 iptables NAT Table인 "KUBE-SVC-*"로 이동합니다.

KUBE-SVC-* Table 관련 규칙
"KUBE-SVC-*" Table에서는 각 Service의 Backend Pod로의 적절한 부하 분산을 위한 규칙이 존재 합니다.
위 예제에서 부하 분산에 대한 확률은 첫 번째 에서 "0.33333" 의 확률로 첫 번째 대상 SEP에 Hit되고, Hit 되지 않는 경우 두 번째 대상 "KUBE-SEP" Table에 대해 "0.5"의 확률로 Hit됩니다. 두 번째 대상 "KUBE-SEP" Table에 대해 "0.5"의 확률인 이유는 iptables의 규칙이 순차적으로 위에서 부터 아래로 평가 되기 때문입니다. 즉, 첫번째 규칙에서 Hit 되지 않았기 때문에 두번째 규칙에서의 확률은 남은 두개의 대상 "KUBE-SEP" Table에 대해 부하 분산을 하기 위해 50%의 확률로 설정 되는 것입니다. 당연히 마지막 대상 "KUBE-SEP" Table까지 오게 되면 남은 선택지는 없기 때문에 해당 규칙에 해당하는 "KUBE-SEP" Table로 이동하게 됩니다.

KUBE-SEP-* Table의 규칙
최종적으로 "KUBE-SEP-*" Table로 이동하게 되면 부하분산을 위해 Source IP에 대한 Masquerading과 DNAT가 수행됩니다. DNAT는 부하분산 된 Pod로 Routing을 위해 수행되고 Source IP에 대한 Masquerading은 최종적으로 요청에 대한 정상적인 응답을 위해 수행 됩니다.
위에서 보신 것 처럼, iptables을 통해 부하분산 및 NAT, Routing이 모두 수행되기 때문에 iptables로 인한 병목이 발생 할 수 있고 앞에서 언급한 여러 잠재적인 문제점들이 발생 할 수 있습니다.
대부분의 상황에는 kubernetes의 CNI가 문제없이 네트워크 통신을 잘 하지만 예외적인 장애상황이 발생했을 때, 파드와 파드간 통신에 있어 그 사이에 여러 홉이 존재하며, 그들 간의 네트워크를 이해해야 한다는 사실은 네트워크 엔지니어가 아니고서야 트러블슈팅에 부담이 생기게 됩니다.
Cilium은 여기에 대해서 다른 방식의 접근을 제시하는 CNI라고 볼 수 있습니다. BPF가 DNAT를 미리 수행하여 사용자가 보는 입장에서 네트워크를 단순화하고 가시성을 좋게 하며, 성능적으로도 보다 나은 효율을 낸다는 점에서 관심을 끌었습니다.
BPF을 활용하면 리눅스 커널내에서 데이터 포워딩을 할 수 있고 Kubernetes Service기반 Load Balancing이나 istio와 같은 Service Mesh를 위한 Proxy Injection 을 통해 여러 활용을 할 수 있을거라고 Cilium 프로젝트는 이야기 하고 있습니다.
출처
eBPF Basic : https://m.blog.naver.com/PostView.naver? blogId=kangdorr&logNo=222593265958&navType=by
Cilium 누구냐 넌? : https://ddii.dev/kubernetes/cilium-1/
Cilium CNI 등장배경 : https://malwareanalysis.tistory.com/288
Cilium CNI pod 통신 : https://malwareanalysis.tistory.com/290
AWS EKS에 Cilium CNI 설치하기 : https://isn-t.tistory.com/42
'eBPF부터 오픈소스까지' 2022년 '관찰가능성' 주요 트렌드 5가지: https://www.itworld.co.kr/news/223914
'IT > Linux OS' 카테고리의 다른 글
| [Linux] ssh에 config를 설정하여 쉽게 서버 접근하기 (0) | 2024.01.02 |
|---|---|
| [Linux] eBPF(Extended Berkeley Packet Filter)란? (0) | 2022.08.26 |
| [Linux] yum repository 설정하기 (0) | 2022.02.28 |
| [리눅스] date 명령어 사용하기 (format 활용법 yyyy-mm-dd) (0) | 2022.02.16 |
| [리눅스] 다중명령어 (더블엔퍼센트&&, 더블버티컬바||) (0) | 2022.02.16 |
